afl分析
代码插桩
如果了解编译过程,那么就知道把源代码编译成二进制,主要是经过”源代码”->”汇编代码”->”二进制”这样的过程。而将汇编代码编译成为二进制的工具,即为汇编器assembler。Linux系统下的常用汇编器是as。不过,编译完成AFL后,在其目录下也会存在一个as文件,并作为符号链接指向afl-as。所以,如果通过-B选项为gcc设置了搜索路径,那么afl-as便会作为汇编器,执行实际的汇编操作。
所以,AFL的代码插桩,就是在将源文件编译为汇编代码后,通过afl-as完成。
afl-as.c中具体插入代码的部分如下:add_instrumentation()函数
1 | fprintf(outf, use_64bit ? trampoline_fmt_64 : trampoline_fmt_32,R(MAP_SIZE)); |
通过fprintf()将格式化字符串添加到汇编文件的相应位置
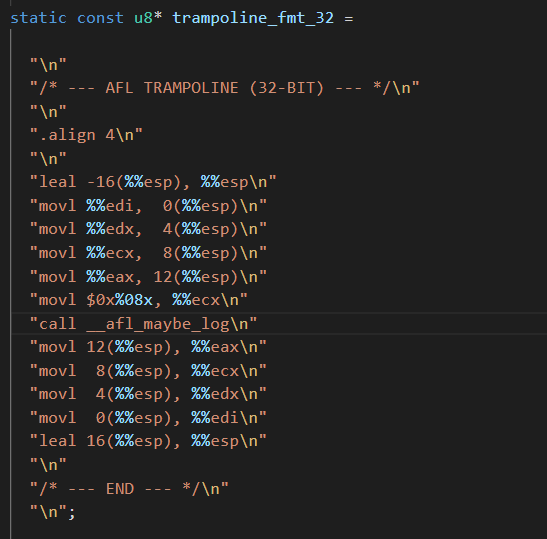
- 保存
edi等寄存器 - 将
ecx的值设置为fprintf()所要打印的变量内容 - 调用方法
__afl_maybe_log() - 恢复寄存器
在跳转处插入了调用random封装而成的R(MAP_SIZE)函数生成一个随机值存入rcx寄存器,再进入堆栈成为_afl_maybe_log的参数。那么当AFL在选择输入种子之后就会运行程序,没到一个基本块就会执行一次_afl_maybe_log,这样一来,每个基本块相当于有了自己的id,afl执行了哪些基本块就会记录id,从而得到执行路径
例子
源码
1 |
|
afl-gcc编译
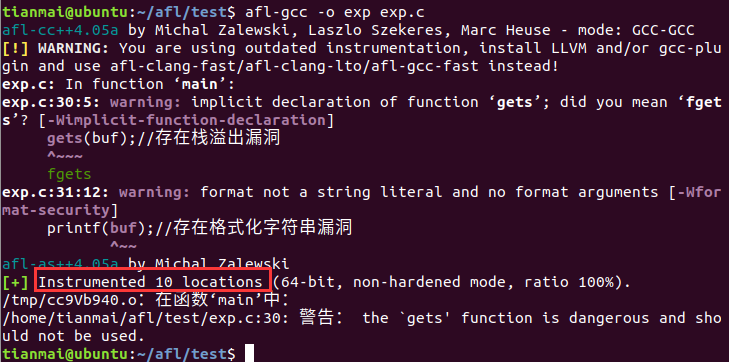
这里显示插了10个桩(源文件编译为汇编代码后,通过afl-as完成)
反汇编
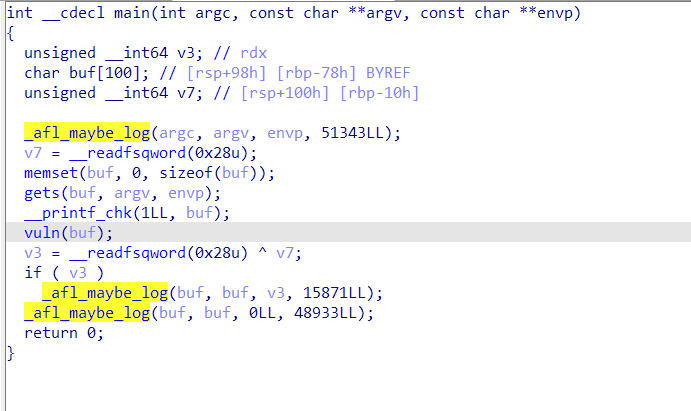
main函数3个
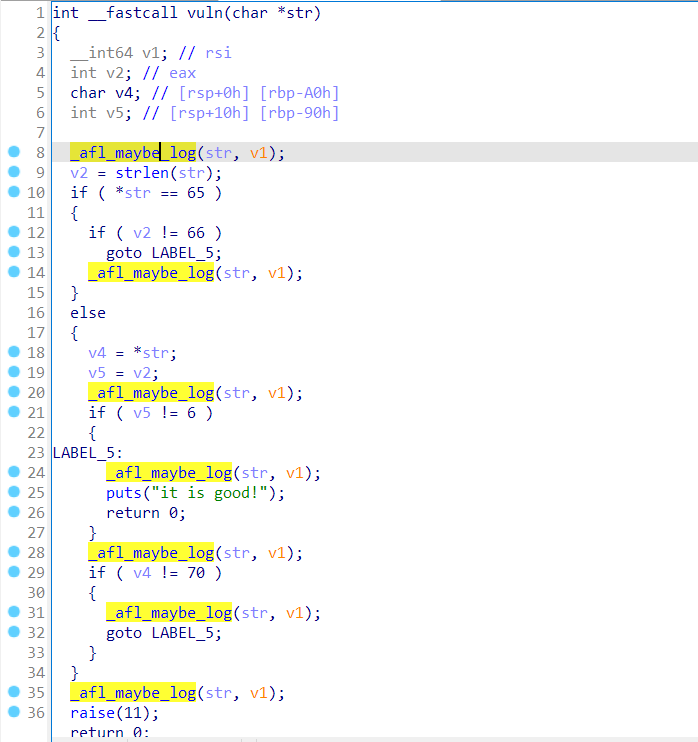
vlun函数7个
gdb调试
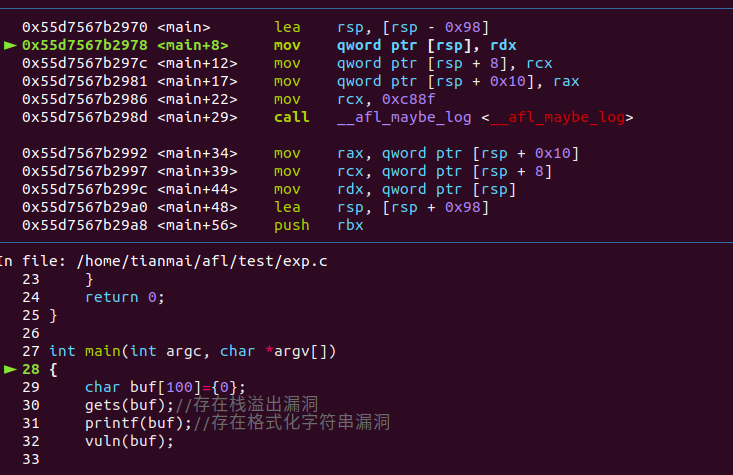
R(MAP_SIZE)生成一个随机数(0到MAP_SIZE之间,MAP_SIZE为64K)这里是0xc88f放到rcx寄存器里,作为标识这个代码块的key。
fork server
编译target完成后,就可以通过afl-fuzz开始fuzzing了。其大致思路是,对输入的seed文件不断地变化,并将这些mutated input喂给target执行,检查是否会造成崩溃。因此,fuzzing涉及到大量的fork和执行target的过程。
所以,afl实现了一套fork server机制
首先,fuzzer执行fork()得到父进程和子进程,这里的父进程仍然为fuzzer,子进程则为target进程,即将来的fork server。
1 | //afl-fuzz.c init_forkserver函数 |
父子进程之间用管道来通信:
1 | int st_pipe[2], ctl_pipe[2]; |
对于子进程(fork server),会进行一系列设置,其中包括将上述两个管道分配到预先指定的fd,并最终执行target:
1 | if (!forksrv_pid) { |
对于父进程(fuzzer),则会读取状态管道的信息,如果一切正常,则说明fork server创建完成
1 | fsrv_st_fd = st_pipe[0]; |
通信
分析fork server是如何与fuzzer通信:
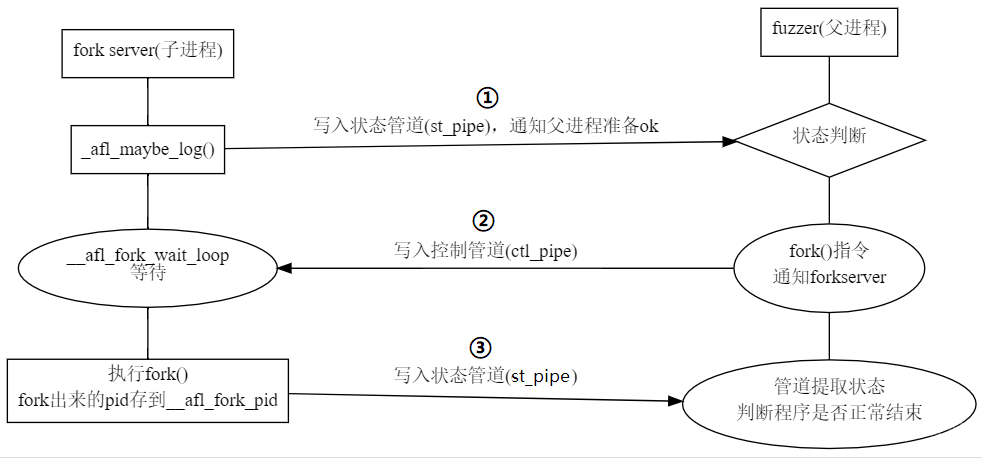
①fork server侧
的具体操作,也是在之前提到的方法__afl_maybe_log()中。首先,通过写入状态管道,fork server会通知fuzzer,其已经准备完毕,可以开始fork了。
1 | //afl_as.h 244 |
fuzzer侧
读取状态管道的信息,如果一切正常,则说明fork server创建完成,具体操作:
1 | //afl-fuzz.c 2108 |
②fork server侧
进入等待状态__afl_fork_wait_loop,读取命令管道,直到fuzzer通知其开始fork:
1 | //afl-as.h 266 |
fuzzer侧
在fork server启动完成后,一旦需要执行某个测试用例,则fuzzer会调用run_target()方法。在此方法中,便是通过命令管道,通知fork server准备fork;并通过状态管道,获取子进程pid:
1 | //afl-fuzz.c 2367 |
③fork server侧
再次读取状态管道,获取子进程退出状态,并由此来判断子进程结束的原因,例如正常退出、超时、崩溃等,并进行相应的记录
1 | //afl-fuzz.c 2407 |
fuzzer侧
一旦fork server接收到fuzzer的信息,便调用fork(),得到父进程和子进程:
1 | //afl-as.h 284 |
将子进程的pid通过状态管道发送给fuzzer,并等待子进程执行完毕;一旦子进程执行完毕,则再通过状态管道,将其结束状态发送给fuzzer;之后再次进入等待状态__afl_fork_wait_loop:
1 | //afl-as.h 572 |
afl运行
main函数中首先识别参数opt = getopt(argc, argv,”+i: o: f: m: t: T: d: n: C: B: S:M: x: Q”)。然后在setup_shm()这个函数中初始化MAP_SIZE(2^16)大小的map用来父进程子进程间的信息共享。然后perform_dry_run()这个函数把初始的种子跑一遍,观察是否有问题。
cull_queue()
种子的数据结构:
1 | struct queue_entry { |
每次通过程序运行该种子的时间、是否产生新路径等信息对种子进行打分排序,对一些没有贡献的种子,pass_det这一项就置为1表示循环fuzz的时候将跳过该种子。
run_target()
不管是在一开始的perform_dry_run()还是后面测试过程中一直循环的fuzz_one(),这个是运行插桩程序的函数。在里面先是查询有没有forkserver这么一个子进程,如果没有就建立一个forkserver,同时建立好管道。
在init_forkserver这个环节,会生成两个管道ctl_pipe, st_pipe,分别绑定fd 198,fd 199.然后开始运行程序并且进程间通信。一旦init了child进程就不会退出,每次有新的测试样例,就直接运行,运行的时候child进程fork一个grandchild进程,这个进程一直运行_afl_store()这个函数对shm的bitmap进行修改。
如果是第一次运行(一般在perform_dry_run()这个函数中),就会创建一个子进程。子进程会一直用testcase这个缓冲区中的种子运行程序,通过管道把执行路径交互给父进程。交互过程如下:
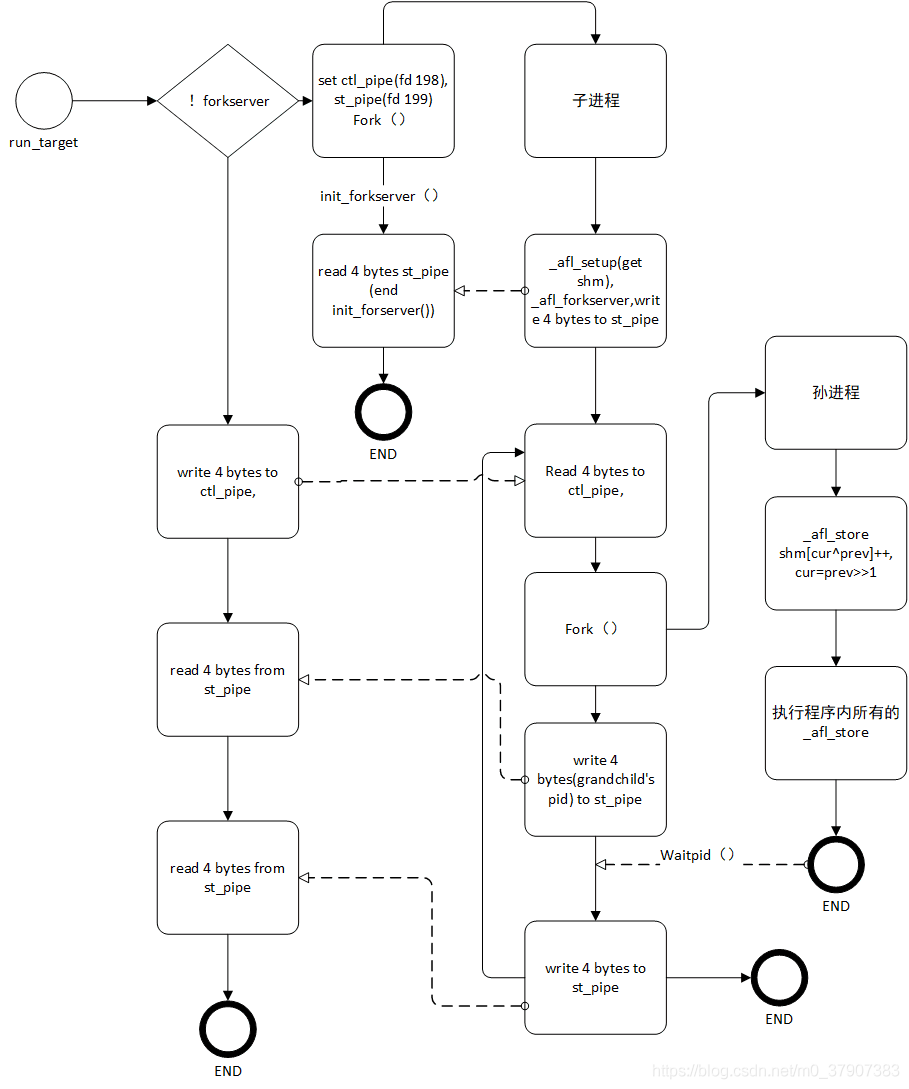
每次运行run_target()函数都会在ctl_pipe写入值,唤醒卡死在read等待的子进程,子进程就可以fork一个孙进程,孙进程执行程序,把所有程序块中插桩的部分执行一遍,把结果写入共享的内存区,就实现了执行路径的记录。
1 | cur_location = <COMPILE_TIME_RANDOM>; |
这里的cur_location和prev_location都是程序块的id,这里使用[cur_location ^ prev_location]意为记录边,因为如果一个程序有a、b、c三个基本块,a->b->c 和a->c->b是不同的执行路径,但是只用基本块记录的话都是a、b、c,用边记录的话可以跟好比对运行路径。
变异 fuzz_one
trim_case()修剪
static u8 trim_case(char** argv, struct queue_entry* q, u8* in_buf)在进行确定性检查时,修剪所有新的测试用例以节省周期。修剪器使用文件大小的1/16到1/1024之间的2次方增量,速度和效率的折中。
step:
- 首先取testcase长度2的指数倍
- 第一个while循环,从文件大小1/16的步长开始,慢慢到文件大小的1/1024倍步长。
- 第二个while循环,嵌套在第一个内,从文件头开始按步长切割testcase,然后target_run();如果删除之后对文件执行路径没有影响那么就将这个删除保存至实际文件中。再删除之前会将trace_bits保存到起来。删除完成之后重新拷贝。如果不清楚看下面代码。
1 | //afl-fuzz.c 4468 |
修剪之后用calculate_score函数打分:
根据case的执行速度/bitmap的大小/case产生时间/路径深度等因素给case进行打分,返回值为一个分数,用来调整在havoc阶段的用时。使得执行时间短,代码覆盖高,新发现的,路径深度深的case拥有更多havoc变异的机会。
bitflip 按位翻转
1变为0,0变为1
拿到一个原始文件,打头阵的就是bitflip,而且还会根据翻转量/步长进行多种不同的翻转,按照顺序依次为:
bitflip 1/1,每次翻转1个bit,按照每1个bit的步长从头开始
bitflip 2/1,每次翻转相邻的2个bit,按照每1个bit的步长从头开始
bitflip 4/1,每次翻转相邻的4个bit,按照每1个bit的步长从头开始
bitflip 8/8,每次翻转相邻的8个bit,按照每8个bit的步长从头开始,即依次对每个byte做翻转
bitflip 16/8,每次翻转相邻的16个bit,按照每8个bit的步长从头开始,即依次对每个word做翻转
bitflip 32/8,每次翻转相邻的32个bit,按照每8个bit的步长从头开始,即依次对每个dword做翻转
生成effector map
在进行bitflip 8/8变异时,AFL还生成了一个非常重要的信息:effector map
1 |
在对每个byte进行翻转时,如果其造成执行路径与原始路径不一致,就将该byte在effector map中标记为1,即“有效”的,否则标记为0,即“无效”的。在随后的一些变异中,会参考effector map,跳过那些“无效”的byte。
arithmetic 整数加/减算术运算
在bitflip变异全部进行完成后,便进入下一个阶段:arithmetic。与bitflip类似的是,arithmetic根据目标大小的不同,也分为了多个子阶段:
- arith 8/8,每次对8个bit进行加减运算,按照每8个bit的步长从头开始,即对文件的每个byte进行整数加减变异
- arith 16/8,每次对16个bit进行加减运算,按照每8个bit的步长从头开始,即对文件的每个word进行整数加减变异
- arith 32/8,每次对32个bit进行加减运算,按照每8个bit的步长从头开始,即对文件的每个dword进行整数加减变异
不会全部变异:1. effector map:如果一个整数的所有bytes都被判断为“无效”,那么就跳过对整数的变异
2. 如果加/减某个数后,其效果与之前的某种bitflip相同,那么这次变异肯定在上一个阶段已经执行过了,便不会再执行
interest 内容替换
把一些特殊内容替换到原文件中
- interest 8/8,每次对8个bit进替换,按照每8个bit的步长从头开始,即对文件的每个byte进行替换
- interest 16/8,每次对16个bit进替换,按照每8个bit的步长从头开始,即对文件的每个word进行替换
- interest 32/8,每次对32个bit进替换,按照每8个bit的步长从头开始,即对文件的每个dword进行替换
而用于替换的”interesting values”,是AFL预设的一些比较特殊的数。这些数的定义在config.h文件中,可以看到,用于替换的基本都是可能会造成溢出的数
1 | //config.h 217 |
dictionary 替换/插入
把自动生成或用户提供的token替换/插入到原文件中
进入到这个阶段,就接近deterministic fuzzing的尾声了。具体有以下子阶段:
user extras (over),从头开始,将用户提供的tokens依次替换到原文件中
user extras (insert),从头开始,将用户提供的tokens依次插入到原文件中
auto extras (over),从头开始,将自动检测的tokens依次替换到原文件中
其中,用户提供的tokens,是在词典文件中设置并通过-x选项指定的,如果没有则跳过相应的子阶段。
*a. user extras (over)*
对于用户提供的tokens,AFL先按照长度从小到大进行排序。这样做的好处是,只要按照顺序使用排序后的tokens,那么后面的token不会比之前的短,从而每次覆盖替换后不需要再恢复到原状。
随后,AFL会检查tokens的数量,如果数量大于预设的MAX_DET_EXTRAS(默认值为200),那么对每个token会根据概率来决定是否进行替换:
1 | for (j = 0; j < extras_cnt; j++) { |
这里的UR(extras_cnt)是运行时生成的一个0到extras_cnt之间的随机数。所以,如果用户词典中一共有400个tokens,那么每个token就有200/400=50%的概率执行替换变异。我们可以修改MAX_DET_EXTRAS的大小来调整这一概率。
由上述代码也可以看到,effector map在这里同样被使用了:如果要替换的目标bytes全部是“无效”的,那么就跳过这一段,对下一段目标执行替换。
b. user extras (insert)
这一子阶段是对用户提供的tokens执行插入变异。不过与上一个子阶段不同的是,此时并没有对tokens数量的限制,所以全部tokens都会从原文件的第1个byte开始,依次向后插入;此外,由于原文件并未发生替换,所以effector map不会被使用。
这一子阶段最特别的地方,就是变异不能简单地恢复。之前每次变异完,在变异位置处简单取逆即可,例如bitflip后,再进行一次同样的bitflip就恢复为原文件。正因为如此,之前的变异总体运算量并不大。
但是,对于插入这种变异方式,恢复起来则复杂的多,所以AFL采取的方式是:将原文件分割为插入前和插入后的部分,再加上插入的内容,将这3部分依次复制到目标缓冲区中(当然这里还有一些小的优化,具体可阅读代码)。
而对每个token的每处插入,都需要进行上述过程。所以,如果用户提供了大量tokens,或者原文件很大,那么这一阶段的运算量就会非常的多。直观表现上,就是AFL的执行状态栏中,”user extras (insert)”的总执行量很大,执行时间很长。如果出现了这种情况,那么就可以考虑适当删减一些tokens
*c. auto extras (over)*
这一项与”user extras (over)”很类似,区别在于,这里的tokens是最开始bitflip阶段自动生成的。另外,自动生成的tokens总量会由USE_AUTO_EXTRAS限制(默认为10)。
havoc 大破坏
对于非dumb mode的主fuzzer来说,完成了上述deterministic fuzzing后,便进入了充满随机性的这一阶段;对于dumb mode或者从fuzzer来说,则是直接从这一阶段开始。
havoc,顾名思义,是充满了各种随机生成的变异,是对原文件的“大破坏”。具体来说,havoc包含了对原文件的多轮变异,每一轮都是将多种方式组合(stacked)而成:
- 随机选取某个bit进行翻转
- 随机选取某个byte,将其设置为随机的interesting value
- 随机选取某个word,并随机选取大、小端序,将其设置为随机的interesting value
- 随机选取某个dword,并随机选取大、小端序,将其设置为随机的interesting value
- 随机选取某个byte,对其减去一个随机数
- 随机选取某个byte,对其加上一个随机数
- 随机选取某个word,并随机选取大、小端序,对其减去一个随机数
- 随机选取某个word,并随机选取大、小端序,对其加上一个随机数
- 随机选取某个dword,并随机选取大、小端序,对其减去一个随机数
- 随机选取某个dword,并随机选取大、小端序,对其加上一个随机数
- 随机选取某个byte,将其设置为随机数
- 随机删除一段bytes
- 随机选取一个位置,插入一段随机长度的内容,其中75%的概率是插入原文中随机位置的内容,25%的概率是插入一段随机选取的数
- 随机选取一个位置,替换为一段随机长度的内容,其中75%的概率是替换成原文中随机位置的内容,25%的概率是替换成一段随机选取的数
- 随机选取一个位置,用随机选取的token(用户提供的或自动生成的)替换
- 随机选取一个位置,用随机选取的token(用户提供的或自动生成的)插入
UR随机函数
splice拼接
历经了如此多的考验,文件的变异也进入到了最后的阶段:splice。如其意思所说,splice是将两个seed文件拼接得到新的文件,并对这个新文件继续执行havoc变异。
具体地,AFL在seed文件队列中随机选取一个,与当前的seed文件做对比。如果两者差别不大,就再重新随机选一个;如果两者相差比较明显,那么就随机选取一个位置,将两者都分割为头部和尾部。
最后,将当前文件的头部与随机文件的尾部拼接起来,就得到了新的文件。在这里,AFL还会过滤掉拼接文件未发生变化的情况。
最后
变量trace_bits来记录分支执行次数
trace_mini 每个bit对应了bit_map中的一个byte;如果这个queue访问了bit_map中的一个byte(即访问了一个edge),trace_mini中对应的bit位就置一
